

Perbedaan antara HBase dan Hive
- 654
- 107
- Grant Zieme
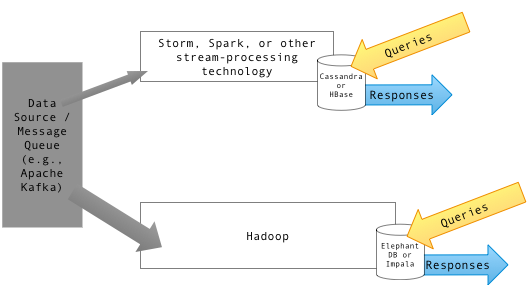
HBase dan Hive keduanya adalah struktur gudang data berbasis Hadoop yang berbeda secara signifikan tentang bagaimana mereka menyimpan dan meminta data. Mengelola dan memproses volume besar data berbasis web menjadi semakin sulit melalui alat manajemen basis data konvensional. Di sinilah HBase datang ke gambar. HBase adalah pilihan yang lebih disukai untuk menangani sejumlah besar data. Misalnya, jika Anda perlu memfilter melalui menyimpan email besar untuk menarik satu untuk audit atau untuk tujuan lain, ini akan menjadi kasus penggunaan yang sempurna untuk HBase. Hive, di sisi lain, lebih seperti sistem pelaporan gudang data tradisional yang berjalan di atas Hadoop. Hive menawarkan bahasa kueri seperti SQL yang memungkinkan Anda untuk menanyakan data semi-terstruktur yang disimpan di Hadoop. Ini membutuhkan upaya yang tidak perlu untuk menulis kode MapReduce. Meskipun, baik HBase dan Hive digunakan sebagai penyimpanan data untuk menyimpan data yang tidak terstruktur, mereka berbeda.
Apa itu hbase?
HBase adalah sistem manajemen basis data sumber terbuka, non-relasional, yang terinspirasi oleh arsitektur tabel besar Google dan ditulis dalam Java. HBase pada dasarnya adalah basis data NoSQL yang berorientasi kolom yang didistribusikan yang berjalan di atas Sistem File Terdistribusi Hadoop (HDFS). Ini dirancang dan dikembangkan oleh banyak insinyur di bawah kerangka Yayasan Perangkat Lunak Apache. Itu duduk di Apache Hadoop dan ditenagai oleh struktur file terdistribusi yang toleran terhadap kesalahan yang dikenal sebagai HDFS. Ini menyediakan cara untuk menyimpan set data yang jarang, yang umum dalam kasus penggunaan data besar. Ini memungkinkan pembacaan cepat data akses acak dari sejumlah besar data berdasarkan nilai kunci. Namun, itu tidak dirancang untuk melakukan agregasi data.
Apa sarangnya?
Hive bukanlah database tetapi paket pergudangan data yang dibangun di atas Hadoop. Hive adalah teknologi yang berbeda dari HBase; Ini menyusun data dalam satu set tabel yang dapat digabungkan, dikumpulkan dan ditanyai menggunakan bahasa kueri yang disebut Hive Query Language (HQL) yang sangat mirip dengan SQL, yang digunakan untuk pemrosesan batch data besar Big Data. Ini memungkinkan Anda untuk menanyakan data semi-terstruktur yang disimpan di Hadoop, yang akhirnya berubah menjadi pekerjaan MapReduce, dieksekusi baik secara lokal atau pada cluster MapReduce yang didistribusikan. Hive pada dasarnya adalah sistem gudang data untuk Hadoop yang memfasilitasi ringkasan data yang mudah, kueri ad-hoc, dan analisis set data besar yang disimpan dalam sistem file yang kompatibel Hadoop. Data dapat dibaca dan ditulis dari Hive dan HBase dan sebaliknya. Namun, itu tidak dapat digunakan untuk pemrosesan data waktu nyata.
Perbedaan antara HBase dan Hive
Teknologi
- Meskipun HBase dan Hive keduanya adalah struktur gudang data berbasis Hadoop yang digunakan untuk menyimpan dan memproses data dalam jumlah besar, mereka berbeda secara signifikan tentang bagaimana mereka menyimpan dan meminta data. HBase pada dasarnya adalah basis data NoSQL yang berorientasi kolom yang didistribusikan yang berjalan di atas Sistem File Terdistribusi Hadoop (HDFS) dan memberikan cara toleran terhadap kesalahan untuk menyimpan set data yang jarang, yang umum dalam kasus penggunaan data besar Big Data Big Data, Big Data User. Hive, di sisi lain, bukanlah database tetapi paket pergudangan data yang dibangun di atas Hadoop. Hive lebih seperti sistem pelaporan pergudangan data tradisional.
Arsitektur
- HBase adalah database NoSQL dan implementasi sumber terbuka dari arsitektur tabel besar Google yang duduk di Apache Hadoop dan ditenagai oleh struktur file terdistribusi yang toleran terhadap kesalahan yang dikenal sebagai HDFS. Ini adalah solusi penyimpanan yang dapat diskalakan untuk mengakomodasi jumlah data yang hampir tak ada habisnya. Ini adalah arsitektur penyimpanan data yang digunakan untuk menyimpan data yang tidak terstruktur. Hive, di sisi lain, adalah mesin SQL yang dibangun di atas HDF dan memanfaatkan MapReduce secara internal, memungkinkan permintaan data yang disimpan pada HDF melalui bahasa kueri seperti SQL yang disebut HQL (bahasa kueri sarang).
Menggunakan
- HBASE digunakan untuk membangun layanan lapisan ubin berbiaya rendah, fleksibel, dan mudah untuk mempertahankan ubin - Sistem Informasi Geografis Berbasis Hadoop (HBGIS) - untuk penyimpanan data besar -besaran. Ini adalah format penyimpanan kolom on-disk yang menyediakan cara untuk menyimpan set data yang jarang, yang umum dalam kasus penggunaan data besar. Ini memungkinkan pembacaan cepat data akses acak dari sejumlah besar data berdasarkan nilai kunci. Hive, di sisi lain, adalah standar untuk kueri SQL atas petabyte data di Hadoop dan menyediakan bahasa kueri seperti SQL yang disebut HQL untuk meminta data yang disimpan dalam cluster Hadoop.
Hbase vs. Hive: Bagan Perbandingan
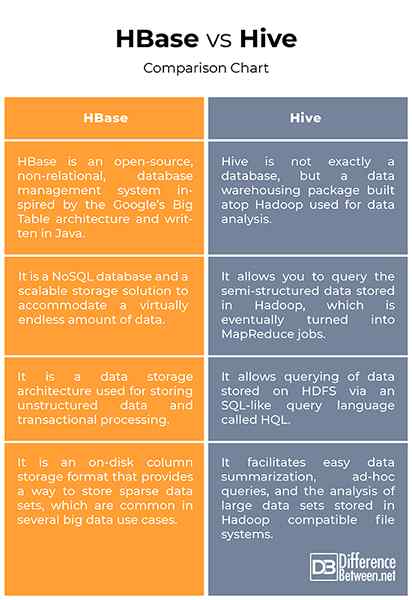
Ringkasan
Meskipun HBase dan Hive keduanya adalah struktur gudang data berbasis Hadoop yang digunakan untuk menyimpan dan memproses data dalam jumlah besar, mereka berbeda secara signifikan tentang bagaimana mereka menyimpan dan meminta data. HBase adalah sistem manajemen basis data yang berorientasi kolom yang digunakan untuk penyimpanan data besar-besaran dan menyediakan cara untuk menyimpan set data yang jarang, yang umum dalam beberapa kasus penggunaan data besar. Hive, di sisi lain, lebih seperti sistem pelaporan gudang data tradisional yang dibangun di atas Hadoop yang digunakan untuk menjalankan pemrosesan melalui pekerjaan jadwal dan kemudian memuat hasilnya ke tabel jenis ringkasan yang dapat ditanyakan lebih lanjut dengan aplikasi klien.