

Perbedaan antara Hadoop dan Mongodb
- 994
- 30
- Mr. Miguel Schultz
Kami telah mendengar istilah data besar untuk beberapa waktu sekarang, tapi apa sebenarnya data besar ini? Jumlah data yang dihasilkan oleh Internet of Things telah meningkat secara dramatis selama bertahun -tahun dan terus meningkat pada tingkat eksponensial. Pemrosesan volume data yang sangat besar ini tidak cocok untuk metode tradisional untuk ditangani disebut sebagai data besar. Jenis data ini menimbulkan tantangan pada sistem RDBMS tradisional yang digunakan untuk menyimpan dan memproses data. Kekuatan pemrosesan yang diperlukan untuk menyimpan dan memproses data sebanyak ini secara tepat waktu dan hemat biaya sangat besar. Untuk mengatasi masalah ini, diperlukan solusi data besar yang baru dan lebih baik yang dirancang khusus untuk memproses data besar yang tidak terstruktur. Dari sekian banyak teknologi, Hadoop dan MongoDB adalah dua pilihan populer dalam hal menyimpan dan memproses data besar. Meskipun keduanya cukup mirip pada dasarnya apa yang mereka lakukan, tetapi pendekatan mereka terhadap bagaimana mereka melakukannya sangat berbeda. Biarkan 'Lihatlah.
Apa itu MongoDB?
MongoDB adalah database dokumen sumber terbuka yang telah berkembang menjadi database de facto noSQL dengan jutaan pengguna, dari startup kecil hingga perusahaan Fortune 500. Perusahaan terkemuka dan perusahaan TI konsumen memanfaatkan kemampuan MongoDB dalam produk dan solusi mereka. Ditulis dalam C ++, MongoDB adalah basis data lintas platform, yang berorientasi dokumen yang secara efektif membahas keterbatasan basis data berbasis skema SQL dengan memberikan solusi berkinerja tinggi, ketersediaan tinggi, dan skalabilitas yang mudah. Ini adalah database yang dirancang untuk web modern. Seperti database NoSQL lainnya, MongoDB tidak mematuhi prinsip -prinsip RDBM tanpa konsep tabel, baris, dan kolom. Ini menyimpan datanya dalam dokumen BSON di mana semua data terkait ditempatkan bersama dalam satu dokumen.
Apa itu Hadoop?
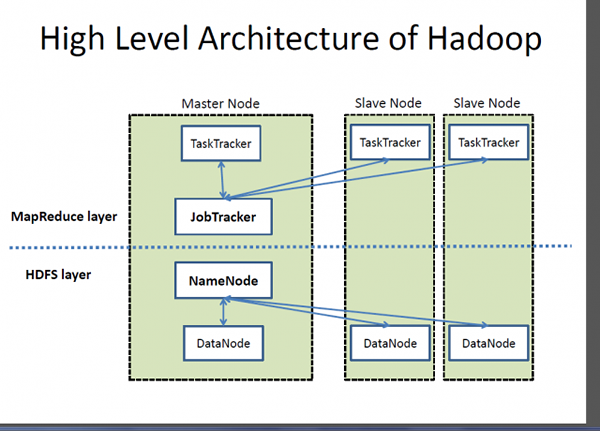
Hadoop adalah kerangka kerja sumber terbuka yang dirancang untuk penyimpanan dan pemrosesan volume data yang sangat besar di seluruh kelompok komputer. Ini adalah aplikasi yang didasarkan pada Java dan kumpulan perangkat lunak berbeda yang menciptakan kerangka kerja pemrosesan data. Idenya adalah untuk memproses data skala besar dengan biaya yang wajar dalam waktu sesedikit mungkin. Hadoop terdiri dari tiga sumber daya utama: Sistem File Terdistribusi Hadoop (HDFS), platform pemrograman MapReduce Google, dan seluruh ekosistem Hadoop. Ekosistem Hadoop terdiri dari modul yang membantu memprogram sistem, mengelola dan mengonfigurasi cluster, mengelola dan menyimpan data dalam cluster dan melakukan tugas analitik. Hadoop MapReduce AIDS Data Analytics Proses dalam jumlah yang sangat besar dari data terstruktur dan tidak terstruktur. Hadoop adalah merek dagang terdaftar dari Apache Software Foundaton dan MapReduce adalah kerangka kerja untuk pemrosesan paralel.
Perbedaan antara Hadoop dan Mongodb
Platform
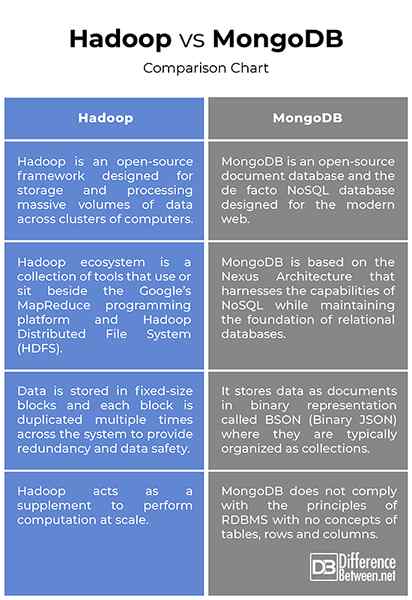
- Meskipun keduanya dianggap sebagai solusi data besar, MongoDB pada dasarnya adalah platform tujuan umum yang dirancang untuk menggantikan atau meningkatkan pada sistem RDBMS yang ada. MongoDB adalah database dokumen sumber terbuka dan salah satu database NoSQL terkemuka yang menggunakan dokumen, bukan baris dan tabel, untuk membuatnya fleksibel, dapat diskalakan, dan cepat. Hadoop, di sisi lain, adalah kerangka kerja open-source yang dirancang untuk penyimpanan dan pemrosesan volume data yang sangat besar di seluruh kelompok komputer. Hadoop tidak dimaksudkan untuk menggantikan sistem RDBMS yang ada; Faktanya, ini bertindak sebagai suplemen untuk membantu analitik data memproses volume besar data terstruktur dan tidak terstruktur.
Arsitektur
- Ekosistem Hadoop adalah kumpulan alat yang digunakan atau duduk di samping platform pemrograman MapReduce Google dan HDFS (Sistem File Terdistribusi Hadoop) untuk menyimpan dan mengatur data, dan mengelola mesin yang menjalankan Hadoop. HDFS dirancang untuk streaming akses data. MongoDB, di sisi lain, menawarkan pendekatan yang berbeda; Ini didasarkan pada arsitektur nexus yang memanfaatkan kemampuan NoSQL sambil mempertahankan fondasi database relasional. Ini menyimpan data sebagai dokumen dalam representasi biner yang disebut BSON (Binary JSON) di mana mereka biasanya diatur sebagai koleksi.
Kekuatan
- Kekuatan terbesar Hadoop adalah MapReduce. Hari ini Hadoop adalah kerangka kerja MapReduce terbaik di pasar. Konsep di balik MapReduce adalah bahwa input dapat dibagi menjadi potongan logis, di mana setiap potongan dapat diproses secara independen dengan tugas peta. Tugas peta dapat berjalan pada simpul komputasi apa pun di cluster dan beberapa tugas peta dapat berjalan secara paralel di seluruh cluster. MongoDB, di sisi lain, adalah database dokumen yang dapat menangani beban mulai dari startup MVP dan POC hingga aplikasi perusahaan dengan ratusan server. MongoDB telah berkembang dari menjadi solusi database niche ke database de facto noSQL. Gagasan dokumennya benar -benar ekspresif dan fleksibel.
Hadoop vs. MongoDB: Bagan Perbandingan
Ringkasan
Meskipun keduanya cukup mirip pada dasarnya apa yang mereka lakukan, tetapi pendekatan mereka terhadap bagaimana mereka melakukannya sangat berbeda. MongoDB menyimpan data sebagai dokumen dalam representasi biner yang disebut BSON, sedangkan di Hadoop, data disimpan dalam blok ukuran tetap dan setiap blok digandakan beberapa kali di seluruh sistem. Ekosistem Hadoop adalah kumpulan alat yang digunakan atau duduk di samping platform pemrograman MapReduce Google, sedangkan MongoDB berdasarkan arsitektur Nexus yang memanfaatkan kemampuan NoSQL sambil mempertahankan dasar database relasional.