

Perbedaan antara Hadoop dan Spark
- 3607
- 836
- Isaac Veum DDS
Salah satu masalah terbesar sehubungan dengan data besar adalah bahwa sejumlah besar waktu dihabiskan untuk menganalisis data yang mencakup mengidentifikasi, membersihkan dan mengintegrasikan data. Volume data yang besar dan persyaratan menganalisis data mengarah ke ilmu data. Tetapi seringkali data tersebar di banyak aplikasi dan sistem bisnis yang membuatnya sedikit sulit untuk dianalisis. Jadi, data perlu direkayasa ulang dan diformat ulang agar lebih mudah dianalisis. Ini membutuhkan solusi yang lebih canggih untuk membuat informasi lebih mudah diakses oleh pengguna. Apache Hadoop adalah salah satu solusi yang digunakan untuk menyimpan dan memproses data besar, bersama dengan sejumlah alat data besar lainnya termasuk Apache Spark. Tapi kerangka mana yang tepat untuk pemrosesan dan analisis data - Hadoop atau Spark? Mari kita cari tahu.
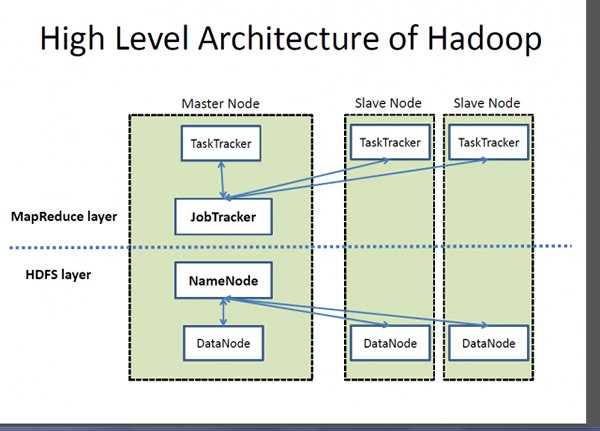
Apache Hadoop
Hadoop adalah merek dagang terdaftar dari Apache Software Foundation dan kerangka kerja open-source yang dirancang untuk menyimpan dan memproses set data yang sangat besar di seluruh kelompok komputer. Ini menangani data skala yang sangat besar dengan biaya yang wajar dalam waktu yang wajar. Selain itu, ini juga menyediakan mekanisme untuk meningkatkan kinerja perhitungan pada skala. Hadoop menyediakan kerangka kerja komputasi untuk menyimpan dan memproses data besar menggunakan model pemrograman MapReduce Google. Ini dapat bekerja dengan server tunggal atau dapat meningkatkan termasuk ribuan mesin komoditas. Meskipun, Hadoop dikembangkan sebagai bagian dari proyek open-source di dalam Yayasan Perangkat Lunak Apache berdasarkan paradigma MapReduce, hari ini ada berbagai distribusi untuk Hadoop. Namun, MapReduce masih merupakan metode penting yang digunakan untuk agregasi dan penghitungan. Ide dasar yang menjadi dasar MapReduce adalah pemrosesan data paralel.

Apache Spark
Apache Spark adalah mesin komputasi cluster open-source dan satu set pustaka untuk pemrosesan data skala besar pada kelompok komputer. Dibangun di atas model Hadoop MapReduce, Spark adalah mesin open-source yang paling aktif untuk membuat analisis data lebih cepat dan membuat program berjalan lebih cepat. Ini memungkinkan analitik real-time dan canggih di platform Apache Hadoop. Inti dari Spark adalah mesin komputasi yang terdiri dari penjadwalan, mendistribusikan dan memantau aplikasi yang terdiri dari banyak tugas komputasi. Tujuan mengemudi utamanya adalah menawarkan platform terpadu untuk menulis aplikasi data besar. Spark awalnya lahir di Laboratorium APM di University of Berkeley dan sekarang ini adalah salah satu proyek open-source teratas di bawah portofolio Apache Software Foundation. Kemampuan komputasi dalam memori yang tak tertandingi memungkinkan aplikasi analitik berjalan hingga 100 kali lebih cepat pada Apache Spark daripada teknologi serupa lainnya di pasaran saat ini.
Perbedaan antara Hadoop dan Spark
Kerangka
- Hadoop adalah merek dagang terdaftar dari Apache Software Foundation dan kerangka kerja open-source yang dirancang untuk menyimpan dan memproses set data yang sangat besar di seluruh kelompok komputer. Pada dasarnya, ini adalah mesin pemrosesan data yang menangani data skala yang sangat besar dengan biaya yang wajar dalam waktu yang wajar. Apache Spark adalah mesin komputasi cluster open-source yang dibangun di atas model MapReduce Hadoop untuk pemrosesan data skala besar dan menganalisis pada kelompok komputer. Spark memungkinkan analitik real-time dan canggih di platform Apache Hadoop untuk mempercepat proses komputasi Hadoop.
Pertunjukan
- Hadoop ditulis di Java sehingga membutuhkan penulisan kode panjang yang membutuhkan lebih banyak waktu untuk pelaksanaan program. Implementasi Hadoop MapReduce yang awalnya dikembangkan adalah inovatif tetapi juga cukup terbatas dan juga tidak terlalu fleksibel. Apache Spark, di sisi lain, ditulis dalam bahasa Scala yang ringkas dan elegan untuk membuat program berjalan lebih mudah dan lebih cepat. Faktanya, ia dapat menjalankan aplikasi hingga 100 kali lebih cepat daripada tidak hanya Hadoop tetapi juga teknologi serupa lainnya di pasaran.
Kemudahan penggunaan
- Paradigma Hadoop Mapreduce inovatif tetapi cukup terbatas dan tidak fleksibel. Program MapReduce dijalankan dalam batch dan mereka berguna untuk agregasi dan penghitungan dalam skala besar. Spark, di sisi lain, menyediakan API yang konsisten dan dapat dikomposisikan yang dapat digunakan untuk membangun aplikasi dari potongan -potongan kecil atau di luar perpustakaan yang ada. API Spark juga dirancang untuk memungkinkan kinerja tinggi dengan mengoptimalkan di berbagai perpustakaan dan fungsi yang disusun bersama dalam program pengguna. Dan karena percikan menyembunyikan sebagian besar data input dalam memori, berkat RDD (dataset terdistribusi yang tangguh), ia menghilangkan kebutuhan untuk memuat beberapa kali ke dalam memori dan penyimpanan disk.
Biaya
- Hadoop File System (HDFS) adalah cara yang efektif biaya untuk menyimpan volume besar data yang terstruktur maupun tidak terstruktur di satu tempat untuk analisis mendalam. Biaya Hadoop per terabyte jauh lebih sedikit daripada biaya teknologi manajemen data lainnya yang digunakan secara luas untuk mempertahankan gudang data perusahaan. Spark, di sisi lain, bukanlah pilihan yang lebih baik dalam hal efisiensi biaya karena membutuhkan banyak RAM untuk cache data dalam memori, yang meningkatkan cluster, karenanya biaya sedikit, dibandingkan dengan Hadoop.
Hadoop vs. Spark: Bagan Perbandingan

Ringkasan Hadoop VS. Percikan
Hadoop bukan hanya alternatif yang ideal untuk menyimpan sejumlah besar data terstruktur dan tidak terstruktur dengan cara yang efektif biaya, tetapi juga menyediakan mekanisme untuk meningkatkan kinerja komputasi pada skala. Meskipun, awalnya dikembangkan sebagai proyek Yayasan Perangkat Lunak Apache Open Source berdasarkan model MapReduce Google, ada berbagai distribusi berbeda yang tersedia untuk Hadoop saat ini. Apache Spark dibangun di atas model MapReduce untuk memperluas efisiensinya untuk menggunakan lebih banyak jenis perhitungan termasuk pemrosesan aliran dan kueri interaktif. Spark memungkinkan analitik real-time dan canggih di platform Apache Hadoop untuk mempercepat proses komputasi Hadoop.