

Perbedaan antara Hadoop dan Cassandra
- 5005
- 804
- Ms. Rene Zieme
Dengan sejumlah besar data yang dihasilkan pada kecepatan yang sangat tinggi dengan ledakan besar Internet of Things dan meningkatkan penggunaan media sosial, kemampuan untuk menyimpan dan menganalisis sejumlah besar data ini telah meningkat. Hadoop adalah salah satu alat canggih yang dirancang untuk menangani sejumlah besar data, yang sering disebut sebagai data besar. Cassandra adalah database lain yang sangat terukur yang mudah digunakan dan dikelola. Tapi yang merupakan pilihan terbaik - Hadoop atau Cassandra?
Apa itu Hadoop?
Apache Hadoop adalah kerangka kerja de facto untuk memproses dan menyimpan volume data yang besar, yang sering disebut sebagai "data besar". Hadoop adalah landasan dari semua solusi data besar. Sebuah proyek oleh Apache Software Foundation, Hadoop adalah sistem pemrosesan terdistribusi skala besar yang dirancang untuk mendistribusikan dan memproses sejumlah besar data di seluruh node di cluster. Ini tidak bertujuan mengganti sistem basis data tradisional; Faktanya, Hadoop memudahkan untuk menggunakan database relasional dengan mempercepat operasi yang terkait dengan set data besar. Hadoop didasarkan pada model pemrograman MapReduce yang terkenal yang cocok untuk pemrosesan set data besar, didistribusikan di seluruh gugusan node, secara paralel. Sistem File Terdistribusi Hadoop (HDFS) adalah sistem file penyimpanan dan pemrosesan data untuk Hadoop yang berjalan pada perangkat keras komoditas dan menyediakan akses paralel, streaming ke sejumlah besar data.
Apa itu Cassandra?
Apache Cassandra adalah basis data sumber terbuka, terdistribusi penuh. Cassandra adalah database non -relasional, juga disebut database NoSQL yang mendasarkan desain distribusinya pada dinamo Amazon dan model datanya di BigTable Google - database NoSQL kinerja tinggi yang dibangun di atas teknologi penyimpanan Google yang berpemilik untuk infrastruktur basis data yang besar yang besar dibangun di atas hakim besar untuk basis data yang besar untuk basis data besar yang besar. Ini adalah sistem manajemen terdistribusi yang dirancang untuk menangani sejumlah besar data terstruktur di seluruh server komoditas. Dibandingkan dengan database terdistribusi populer lainnya seperti HBase, Voldermort, dan Riak, Apache Cassandra menawarkan antarmuka yang kuat dan ekspresif untuk pemodelan dan data kueri. Bagian terbaik tentang Cassandra adalah didistribusikan artinya ia mampu berjalan di beberapa mesin.
Perbedaan antara Hadoop dan Cassandra
Definisi
- Hadoop adalah kerangka kerja open-source apache yang ditulis dalam java yang dirancang untuk menangani sejumlah besar data yang perlu diproses pada skala ketika Anda memproses banyak data pada saat yang sama dengan cara streaming atau dengan cara seperti batch seperti batch. Apache Cassandra, di sisi lain, adalah database yang sangat terukur dan didistribusikan sepenuhnya yang dirancang untuk menangani sejumlah besar data terstruktur di seluruh server komoditas. Apache Cassandra menawarkan antarmuka yang kuat dan ekspresif untuk pemodelan dan data kueri.
Penyebaran
- Hadoop adalah kerangka kerja yang dapat diskalakan yang dirancang untuk digunakan pada perangkat keras berbiaya rendah. Penyimpanan HDFS tersebar di sekelompok node; Satu file besar dapat disimpan di beberapa node di cluster. Itu digunakan di pusat data tunggal, tetapi mereka semua berlokasi geografis satu sama lain. Cassandra, di sisi lain, dikerahkan dengan cara yang sangat terdistribusi sebagai sekelompok contoh yang semuanya sadar. Data dapat dibaca atau ditulis ke contoh apa pun di cluster, disebut sebagai node, yang akan meneruskan permintaan ke instance di mana data berada.
Kerangka
- Apache Hadoop adalah kerangka pemrosesan data besar berdasarkan model pemrograman MapReduce yang terkenal yang cocok untuk pemrosesan set data besar, didistribusikan di seluruh gugusan node, secara paralel. Ini adalah sistem pemrosesan terdistribusi yang dirancang untuk mendistribusikan dan memproses sejumlah besar data di seluruh node di cluster. Cassandra, di sisi lain, adalah database NoSQL yang didistribusikan sepenuhnya yang menawarkan antarmuka yang kuat dan ekspresif untuk pemodelan dan data kueri. Ini tidak seperti sistem database tradisional; Bahkan, ia menyimpan data dalam pasangan nilai kunci. Tidak seperti Hadoop, Cassandra terutama digunakan untuk pemrosesan data real-time.
Format data
- Hadoop dapat bekerja dengan segala jenis data dalam berbagai format, apakah itu terstruktur, semi-terstruktur, atau tidak terstruktur, dan apa pun yang dapat Anda pikirkan-gambar, JSON, XML, dan sebagainya. Cassandra, di sisi lain, adalah sistem manajemen terdistribusi yang dirancang untuk menangani sejumlah besar data terstruktur di seluruh server komoditas. Selain itu, Cassandra tidak mendukung gambar.
Arsitektur
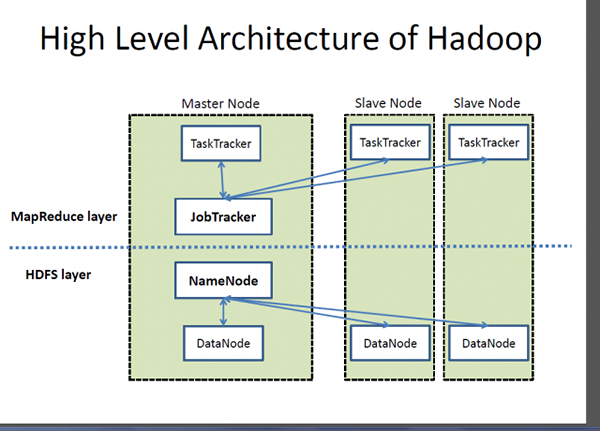
- Hadoop mengikuti arsitektur slave utama yang terdiri dari node utama dan node budak. Namemode adalah node master dan datasodes adalah node budak. Biasanya, daemon datalode berjalan pada setiap mode budak dan mengelola penyimpanan yang terpasang pada setiap datasode. HDF dapat digunakan pada berbagai mesin yang menjalankan java. Cassandra, di sisi lain, menyimpan data pada node yang berbeda dengan sistem terdistribusi peer-to-peer, membuatnya lebih mudah untuk mengoperasikan dan memelihara toko yang terdesentralisasi daripada toko master/slave karena semua node sama.
Hadoop vs. Cassandra: Bagan Perbandingan

Ringkasan
Hadoop adalah landasan solusi data besar yang menawarkan platform mutakhir untuk menyimpan dan menganalisis sejumlah besar set data dan meningkatkan sistem manajemen database relasional tradisional. Apache Hadoop menyediakan kerangka kerja yang toleran terhadap kesalahan untuk penyimpanan dan pemrosesan set data yang sangat besar di seluruh kelompok komoditas. Cassandra adalah database NoSQL terkemuka yang mengambil kemajuan teknologi terbaik dari Dynamo dan Bigtable Papers untuk menangani sejumlah besar data terstruktur di seluruh server komoditas. Selain itu, Cassandra sangat bagus untuk transaksi online yang cepat sementara Hadoop sangat ideal untuk penyimpanan dan pengambilan data yang lebih cepat.