

Perbedaan antara Big Data dan Hadoop

- 2563
- 671
- Mr. Doug Effertz
Hubungan antara Big Data dan Hadoop adalah salah satu topik penting yang menarik di antara para pemula. Dan perbedaan antara dua konsep terkait ini agak menarik. Big Data adalah aset berharga yang tanpa pawang tidak ada gunanya. Jadi, Hadoop adalah pawang yang membawa nilai terbaik dari aset. Mari kita perhatikan keduanya diikuti oleh perbedaan antara keduanya.
Apa itu Big Data?
Di dunia digital saat ini, kita dikelilingi oleh sebagian besar data. Sudah cukup untuk mengatakan bahwa data ada di mana -mana. Evolusi cepat Internet dan Internet of Devices (IoT), dan pemanfaatan media elektronik yang berkelanjutan telah menyebabkan kelahiran e-commerce dan media sosial. Akibatnya, sejumlah besar data telah dihasilkan dan pada kenyataannya, masih menghasilkan setiap hari. Namun, data tidak ada gunanya kecuali Anda memiliki keterampilan yang diperlukan untuk menganalisisnya. Data dalam bentuk saat ini adalah data mentah, yang sebagian besar adalah konten yang dibuat pengguna, yang perlu dianalisis dan disimpan. Data dihasilkan dari berbagai sumber dari media sosial hingga sistem tertanam/sensorik, log mesin, situs e-commerce, dll. Memproses jumlah data yang gila seperti itu menantang. Big Data adalah istilah payung yang mengacu pada banyak cara bagaimana data dapat dikelola dan diproses secara sistematis dalam skala besar. Big Data mengacu pada set data besar dan kompleks yang terlalu rumit untuk dianalisis dengan aplikasi pemrosesan data tradisional.
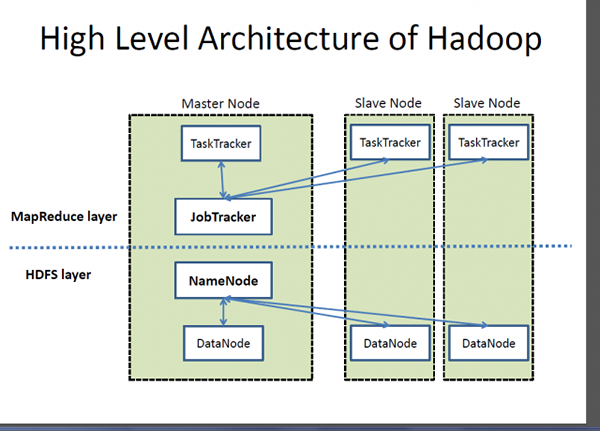
Apa itu Hadoop?
Jika Big Data adalah aset yang sangat berharga, Hadoop adalah program atau alat untuk mengeluarkan nilai terbaik dari aset itu. Hadoop adalah program utilitas perangkat lunak open-source yang dikembangkan untuk menangani masalah menyimpan dan memproses set data yang besar dan kompleks. Apache Hadoop mungkin merupakan salah satu kerangka kerja perangkat lunak yang paling populer dan banyak digunakan untuk menyimpan dan memproses data besar. Ini adalah model pemrograman yang disederhanakan yang memungkinkan Anda untuk menulis dan memeriksa sistem terdistribusi dengan mudah dan distribusi pengetahuan yang secara ekonomis dan ekonomis di seluruh komoditas server yang dikelompokkan. Apa yang membuat Hadoop khas adalah kemampuannya untuk meningkatkan dari satu server ke ribuan mesin server komoditas. Sederhananya, Apache Hadoop adalah kerangka perangkat lunak de facto untuk menyimpan dan memproses data dalam jumlah besar, apa yang sering disebut sebagai data besar. Dua komponen utama ekosistem Hadoop adalah Sistem File Terdistribusi Hadoop (HDFS) dan model pemrograman MapReduce.
Perbedaan antara Big Data dan Hadoop
Dasar -dasar
- Data besar dan Hadoop adalah dua istilah yang paling akrab terkait erat satu sama lain dengan cara yang tanpa Hadoop, data besar tidak akan memiliki makna atau nilai. Pikirkan data besar sebagai aset bernilai mendalam, tetapi untuk mengeluarkan nilai dari aset itu, Anda membutuhkan jalan. Jadi, Apache Hadoop adalah program utilitas yang dirancang untuk memberikan nilai terbaik dari Big Data. Big Data mengacu pada set data besar dan kompleks yang terlalu rumit untuk dianalisis dengan aplikasi pemrosesan data tradisional. Apache Hadoop adalah kerangka kerja perangkat lunak yang digunakan untuk menangani masalah menyimpan dan memproses set data yang besar dan kompleks.
Konsep
- Data dalam bentuk mentahnya tidak ada gunanya dan sangat sulit untuk dikerjakan kecuali jika Anda mengonversi entitas mentah ini yang disebut data menjadi informasi. Kita dikelilingi oleh banyak data yang kita lihat dan memanfaatkan di era digital ini. Misalnya, kami memiliki begitu banyak konten di situs dan aplikasi media sosial seperti Twitter, Instagram, YouTube, dll. Jadi, data besar mengacu pada sejumlah besar data terstruktur dan tidak terstruktur dan informasi yang bisa kita dapatkan dari data ini, seperti pola, tren atau apa pun yang akan membantu membuat data ini lebih mudah untuk dikerjakan. Hadoop adalah kerangka kerja perangkat lunak terdistribusi yang menangani penyimpanan dan pemrosesan set data besar di seluruh komoditas server berkerumun.
Sasaran
- Data dalam bentuk saat ini adalah data mentah, yang sebagian besar adalah konten yang dibuat pengguna, yang perlu dianalisis dan disimpan. Kumpulan data tumbuh pada kecepatan eksponensial dan mereka tumbuh di luar kendali. Jadi, kita perlu cara menangani semua data terstruktur dan tidak terstruktur ini dan kita membutuhkan model pemrograman sederhana yang akan memberikan solusi yang tepat untuk dunia data besar. Ini membutuhkan model komputasi skala besar yang bertentangan dengan model komputasi tradisional. Apache Hadoop adalah sistem terdistribusi yang memungkinkan perhitungan didistribusikan di beberapa mesin alih -alih menggunakan mesin tunggal. Ini dirancang untuk mendistribusikan dan memproses data dalam jumlah besar di seluruh node di cluster.
Data besar vs. Hadoop: Bagan Perbandingan
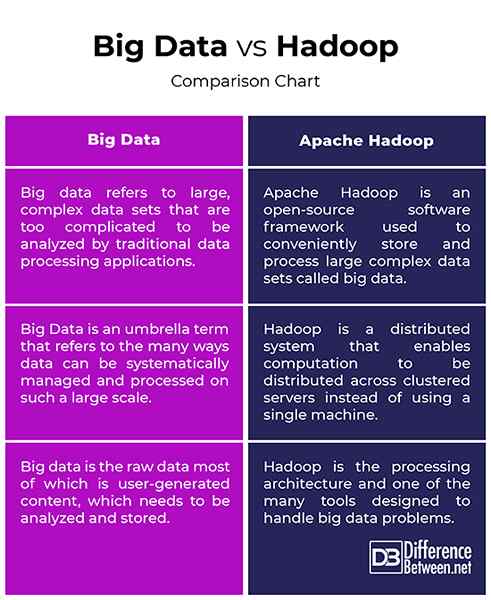
Ringkasan Big Data VS. Hadoop
Big Data adalah aset yang sangat berharga yang tidak ada gunanya kecuali kita menemukan cara untuk mengerjakannya. Aplikasi media sosial seperti Twitter, Facebook, Instagram, YouTube, dll. adalah contoh kehidupan nyata dari data besar yang menimbulkan beberapa tantangan bagi teknologi yang kita gunakan hari ini. Data yang berkembang pesat ini dengan konten yang tidak terstruktur umumnya disebut sebagai data besar. Tapi, data dalam bentuk mentahnya sangat sulit untuk dikerjakan. Kami membutuhkan cara untuk memperoleh, menyimpan, memproses dan menganalisis data ini sehingga kami bisa mendapatkan sesuatu yang berguna darinya, seperti beberapa pola atau tren. Hadoop adalah alat yang membantu menyimpan dan memproses set data kompleks yang terlalu besar untuk ditangani menggunakan teknik dan alat komputasi tradisional.