

Perbedaan antara ORC dan Parket
- 3911
- 1217
- Virgil Hartmann IV
Baik Orc dan Parket adalah format penyimpanan file kolom open-source populer di ekosistem Hadoop dan mereka sangat mirip dalam hal efisiensi dan kecepatan, dan yang terpenting, mereka dirancang untuk mempercepat beban kerja analitik data besar. Bekerja dengan file ORC sama sederhana seperti bekerja dengan file parket karena mereka menawarkan kemampuan membaca dan menulis yang efisien di atas rekan berbasis baris mereka. Keduanya memiliki bagian pro dan kontra yang adil, dan sulit untuk mengetahui mana yang lebih baik dari yang lain. Mari kita perhatikan masing -masing dari masing -masing. Kami akan mulai dengan ORC terlebih dahulu, lalu pindah ke parket.
Orc
ORC, kependekan dari kolumnar baris yang dioptimalkan, adalah format penyimpanan kolumnar open-source yang dirancang untuk beban kerja Hadoop. Seperti namanya, ORC adalah format file yang menggambarkan diri sendiri dan dioptimalkan yang menyimpan data di kolom yang memungkinkan pengguna membaca dan mendekompres hanya bagian yang mereka butuhkan. Ini adalah penerus format file kolom rekaman tradisional (RCFILE) yang dirancang untuk mengatasi keterbatasan format file sarang lainnya. Dibutuhkan waktu yang jauh lebih sedikit untuk mengakses data dan juga mengurangi ukuran data hingga 75 persen. ORC menyediakan cara yang lebih efisien dan lebih baik untuk menyimpan data untuk diakses melalui solusi SQL-on-Hadoop seperti Hive menggunakan TEZ. ORC memberikan banyak keuntungan dibandingkan format file sarang lainnya seperti kompresi data tinggi, kinerja yang lebih cepat, fitur push down prediktif, dan lebih banyak lagi, data yang disimpan diatur ke dalam garis -garis, yang memungkinkan bacaan besar dan efisien dari HDFS.
Parket
Parket adalah format file berorientasi kolom open-source lainnya di ekosistem Hadoop yang didukung oleh Cloudera, bekerja sama dengan Twitter. Parket sangat populer di kalangan praktisi data besar karena memberikan sejumlah besar optimasi penyimpanan, terutama dalam beban kerja analitik. Seperti ORC, Parket memberikan kompresi kolom menghemat banyak ruang penyimpanan sambil memungkinkan Anda membaca masing -masing kolom alih -alih membaca file lengkap. Ini memberikan keuntungan yang signifikan dalam persyaratan kinerja dan penyimpanan sehubungan dengan solusi penyimpanan tradisional. Lebih efisien dalam melakukan operasi gaya IO dan sangat fleksibel dalam hal mendukung struktur data bersarang yang kompleks. Faktanya, ini secara khusus dirancang dengan mengingat struktur data bersarang. Parket juga merupakan format file yang lebih baik dalam mengurangi biaya penyimpanan dan mempercepat langkah membaca ketika datang ke set data yang besar. Parket bekerja sangat baik dengan Apache Spark. Faktanya, ini adalah format file default untuk menulis dan membaca data di Spark.
Perbedaan antara ORC dan Parket
Asal
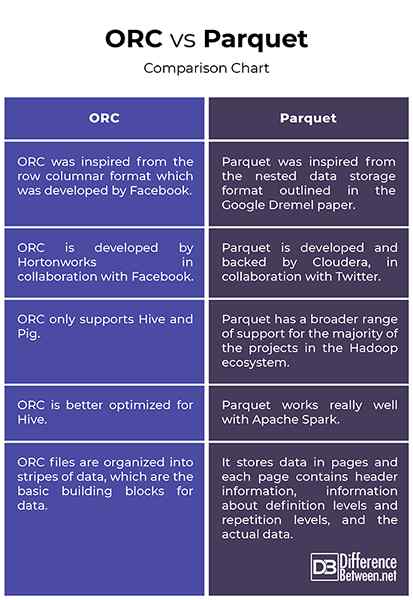
- ORC terinspirasi dari format kolom baris yang dikembangkan oleh Facebook untuk mendukung bacaan kolom, prediktif pushdown dan bacaan malas. Ini adalah penerus format file kolom rekaman tradisional (rcfile) dan memberikan cara yang lebih efisien untuk menyimpan data relasional daripada rcfile, mengurangi ukuran data hingga 75 persen. Parket, di sisi lain, terinspirasi dari format penyimpanan data bersarang yang diuraikan dalam kertas Google Dremel dan dikembangkan oleh Cloudera, bekerja sama dengan Twitter. Parket sekarang menjadi proyek Inkubator Apache.
Mendukung
- Baik Orc dan Parket adalah format file data besar berorientasi kolom yang populer yang berbagi hampir desain serupa karena keduanya berbagi data di kolom. Sementara parket memiliki banyak dukungan yang lebih luas untuk sebagian besar proyek di ekosistem Hadoop, ORC hanya mendukung Hive dan Pig. Salah satu perbedaan utama antara keduanya adalah bahwa ORC lebih dioptimalkan untuk sarang, sedangkan parket bekerja sangat baik dengan Apache Spark. Faktanya, parket adalah format file default untuk menulis dan membaca data di Apache Spark.
Pengindeksan
- Bekerja dengan file orc sama sederhana seperti bekerja dengan file parket. Keduanya bagus untuk beban kerja yang dibaca. Namun, file ORC diatur ke dalam garis -garis data, yang merupakan blok bangunan dasar untuk data dan tidak tergantung satu sama lain. Setiap garis memiliki indeks, data baris dan footer. Footer adalah tempat statistik utama untuk setiap kolom dalam garis seperti Count, Min, Max, dan Sum di -cache. Parket, di sisi lain, menyimpan data di halaman dan setiap halaman berisi informasi header, informasi tentang tingkat definisi dan tingkat pengulangan, dan data aktual.
Orc vs. Parket: Bagan Perbandingan
Ringkasan
Baik Orc dan Parket adalah dua format penyimpanan file yang berorientasi kolom open-source yang paling populer di ekosistem Hadoop yang dirancang untuk bekerja dengan baik dengan beban kerja analisis data. Parket dikembangkan oleh Cloudera dan Twitter bersama -sama untuk mengatasi masalah dengan menyimpan set data besar dengan kolom tinggi. ORC adalah penerus spesifikasi rcfile tradisional dan data yang disimpan dalam format file ORC diatur ke dalam garis -garis, yang sangat dioptimalkan untuk operasi baca HDFS. Parket, di sisi lain, adalah pilihan yang lebih baik dalam hal kemampuan beradaptasi jika Anda menggunakan beberapa alat di ekosistem Hadoop. Parket lebih dioptimalkan untuk digunakan dengan Apache Spark, sedangkan ORC dioptimalkan untuk Hive. Tetapi sebagian besar, keduanya sangat mirip tanpa perbedaan yang signifikan antara keduanya.