

Perbedaan antara Hadoop dan SQL
- 2313
- 686
- Herbert Konopelski
Istilah 'Big Data' adalah salah satu kata kunci terpanas di era digital saat ini. Setiap perusahaan mulai dari startup kecil hingga perusahaan besar memiliki uang untuk data besar. Tiba-tiba kami melihat konvergensi tren signifikan yang secara fundamental mengubah industri dan ada ledakan data karena meningkatnya jumlah perangkat yang terhubung ke internet. Big Data persis di mana kerangka kerja open-source Hadoop datang ke gambar. Hadoop menyediakan kerangka kerja untuk menyimpan dan mengambil sejumlah besar data untuk pemrosesan dan tujuan analitik. Tapi bagaimana Hadoop berbeda dari sistem manajemen basis data lainnya seperti SQL Server? Kami menyoroti beberapa perbedaan utama antara SQL dan Hadoop.
Apa itu Hadoop?
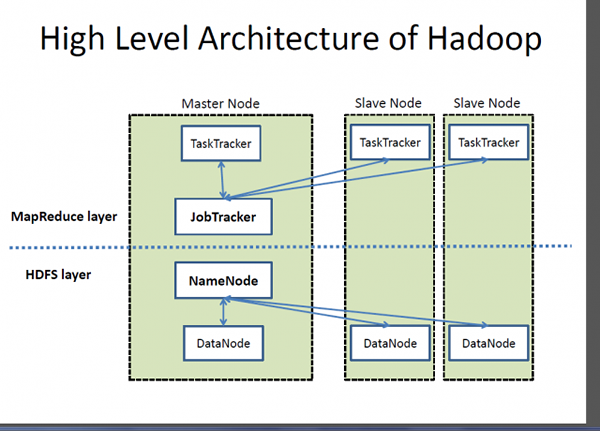
Hadoop adalah kerangka pemrosesan terdistribusi open-source yang dirancang untuk memenuhi kebutuhan perusahaan web untuk mengindeks dan memproses volume data yang sangat besar, berkat peningkatan peningkatan perangkat yang diaktifkan internet dan evolusi besar berikutnya yang disebut media sosial berikutnya. Google memberikan inspirasi untuk pengembangan yang kemudian dikenal sebagai Hadoop. Ini menyediakan kerangka kerja yang memungkinkan pemrosesan volume data yang sangat besar untuk memberikan akses yang mudah dan memuat data secara dinamis.
Apa itu SQL?
SQL telah menjadi alat di mana -mana untuk mengakses dan memanipulasi data dalam database. SQ Server tidak lagi merupakan sistem manajemen basis data reguler yang digunakan oleh pengembang dan administrator dan analis database. Ini adalah ekosistem besar alat dan layanan perbedaan yang bekerja bersama untuk memberikan tugas manajemen platform data yang sangat kompleks. Ini adalah bahasa de facto untuk sistem pendukung transaksional dan keputusan dan alat intelijen bisnis untuk mengakses permintaan iklan berbagai sumber data. Faktanya, SQL Server menangani menegakkan kualitas dan konsistensi data jauh lebih baik dari Hadoop.
Perbedaan antara Hadoop dan SQL
Alat
- Hadoop adalah proyek Yayasan Perangkat Lunak Apache dan kerangka kerja perangkat lunak pemrosesan terdistribusi sumber terbuka untuk menyimpan dan memproses masuknya data yang sangat besar dan menjalankan aplikasi pada kelompok perangkat keras komoditas. Hadoop menyediakan kerangka kerja yang memungkinkan pemrosesan volume data yang sangat besar untuk memberikan akses yang mudah dan memuat data secara dinamis. SQL, kependekan dari bahasa kueri terstruktur, di sisi lain, adalah bahasa de facto untuk sistem pendukung transaksional dan keputusan dan alat intelijen bisnis untuk mengakses dan meminta berbagai data dari berbagai sumber. SQL telah menjadi alat di mana -mana untuk mengakses, memanipulasi, dan menyimpan data dalam database.
Kerangka Hadoop VS. SQL
- Inti dari ekosistem Hadoop adalah dua komponen utama - Sistem File Terdistribusi Hadoop (HDFS) - sistem file yang didistribusikan, terukur dan portabel yang ditulis di Java untuk menyimpan set data yang sangat besar di seluruh kelompok komputer; dan pendekatan untuk pemrosesan terdistribusi berdasarkan Java yang disebut MapReduce. SQL Server, di sisi lain, adalah sistem manajemen basis data relasional dan salah satu platform data paling kuat di dunia yang digunakan oleh sejumlah produk komersial dan in-house untuk meminta, memanipulasi, dan memvisualisasikan berbagai sumber data.
Tipe data
- Hadoop dirancang untuk bekerja dengan tipe data apa pun, apakah itu terstruktur, semi-terstruktur atau tidak terstruktur, membuatnya sangat fleksibel untuk bekerja dengan ketika datang ke pemrosesan data besar. SQL, di sisi lain, adalah bahasa pemrograman yang dibuat khusus untuk mengelola dan meminta data dalam sistem manajemen database relasional (RDBMS). Ini didasarkan pada model hubungan entitas RDBMS, sehingga hanya dapat memproses data terstruktur. SQL tidak dapat digunakan untuk data yang tidak terstruktur karena tidak sesuai dengan model data tanpa struktur yang mudah diidentifikasi.
Pengolahan
- HDFS adalah sistem file terdistribusi yang dirancang untuk mendukung pemrosesan batch data makna data dikumpulkan dalam batch dan setiap batch dikirim untuk diproses. Batch bisa jadi apa saja dari satu hari hingga satu menit. Karena dirancang untuk pemrosesan batch, ia tidak memiliki konsep bacaan acak atau menulis. SQL Server, sebaliknya, sebagai platform basis data tujuan umum, mendukung pemrosesan data real-time, yang berarti data dialirkan dari pengirim ke penerima segera setelah diproduksi di ujung sumber.
Kinerja Hadoop dan SQL
- Arsitektur Hadoop terkadang mengarah pada ketidakcocokan impedansi antara penyimpanan data dan akses data. Ini memiliki lebih sedikit batasan atau validasi pada data yang disimpannya, dan tidak memiliki kemampuan dan ekosistem pengguna akhir yang sama dengan yang dikembangkan SQL. SQL Server, di sisi lain, menangani menegakkan kualitas dan konsistensi data yang jauh lebih baik daripada Hadoop yang memungkinkannya untuk memanfaatkan ekosistem analisis data berbasis SQL dan alat visualisasi data. Namun, SQL juga memiliki beberapa kelemahan yang mencakup skalabilitas untuk menangani sejumlah besar data dan dukungan untuk menyimpan data yang diformat secara longgar.
Hadoop vs. SQL: Bagan Perbandingan

Ringkasan Hadoop VS. SQL
Hadoop adalah alat data besar yang paling disukai dan diterima secara luas yang dirancang untuk bekerja dengan tipe data apa pun - terstruktur, tidak terstruktur, atau semi -terstruktur. Tetapi ketika datang ke RDBMS, SQL mungkin adalah sistem penyimpanan dan manajemen data yang paling kuat, dalam memori dan dinamis. Namun, solusi RDBMS yang ada seperti server SQL hanya untuk mengelola volume data yang signifikan, tetapi tidak untuk data yang tidak terstruktur atau semi-terstruktur dengan atribut variabel. Seperti banyak platform, Hadoop dan SQL Server keduanya memiliki kekuatan dan kelemahan yang adil. Gunakan keduanya bersama -sama dan Anda dapat memanfaatkan kekuatan masing -masing sambil mengurangi kelemahan.
- « Perbedaan antara pengenalan ucapan dan pemrosesan bahasa alami
- Perbedaan antara biosensor dan biochip »