

Perbedaan antara kantong dan hutan acak
- 4252
- 638
- Dana Schmitt DDS
Selama bertahun -tahun, beberapa sistem classifier, juga disebut sistem ensemble telah menjadi topik penelitian yang populer dan menikmati meningkatnya perhatian dalam kecerdasan komputasi dan komunitas pembelajaran mesin. Itu menarik minat para ilmuwan dari beberapa bidang termasuk pembelajaran mesin, statistik, pengenalan pola, dan penemuan pengetahuan dalam database. Seiring waktu, metode ensembel telah membuktikan diri mereka sangat efektif dan serbaguna dalam spektrum luas domain masalah dan aplikasi dunia nyata. Awalnya dikembangkan untuk mengurangi varian dalam sistem pengambilan keputusan otomatis, metode ensemble sejak itu telah digunakan untuk mengatasi berbagai masalah pembelajaran mesin. Kami menyajikan tinjauan umum dari dua algoritma ensemble yang paling menonjol - mengantongi dan hutan acak - dan kemudian membahas perbedaan antara keduanya.
Dalam banyak kasus, mengantongi, yang menggunakan pengambilan sampel bootstrap, tress klasifikasi telah terbukti memiliki akurasi yang lebih tinggi daripada pohon klasifikasi tunggal. Bagging adalah salah satu algoritma berbasis ensemble tertua dan paling sederhana, yang dapat diterapkan pada algoritma berbasis pohon untuk meningkatkan keakuratan prediksi. Ada versi lain yang disempurnakan dari kantong yang disebut algoritma hutan acak, yang pada dasarnya merupakan ansambel pohon keputusan yang dilatih dengan mekanisme mengantongi. Mari kita lihat bagaimana algoritma hutan acak bekerja dan bagaimana perbedaannya dari mengantongi dalam model ensemble.
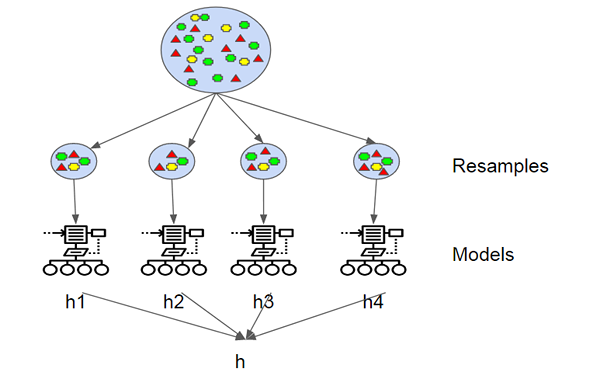
Mengantongi
Agregasi bootstrap, juga dikenal sebagai Bagging, adalah salah satu algoritma berbasis ensemble paling awal dan paling sederhana untuk membuat pohon keputusan lebih kuat dan untuk mencapai kinerja yang lebih baik. Konsep di balik kantong adalah untuk menggabungkan prediksi beberapa pelajar dasar untuk membuat output yang lebih akurat. Leo Breiman memperkenalkan algoritma mengantongi pada tahun 1994. Dia menunjukkan bahwa agregasi bootstrap dapat membawa hasil yang diinginkan dalam algoritma pembelajaran yang tidak stabil di mana perubahan kecil pada data pelatihan dapat menyebabkan variasi besar dalam prediksi. Bootstrap adalah sampel dari dataset dengan penggantian dan setiap sampel dihasilkan dengan pengambilan sampel secara seragam, set pelatihan berukuran M hingga set baru dengan instance M diperoleh.
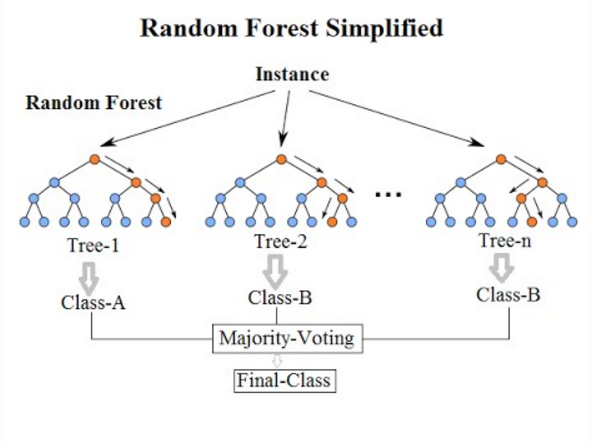
Hutan acak
Random Forest adalah algoritma pembelajaran mesin yang diawasi berdasarkan pembelajaran ensemble dan evolusi algoritma mengantongi asli Breiman. Ini adalah perbaikan besar atas pohon keputusan yang dikantongi untuk membangun beberapa pengambilan keputusan dan mengumpulkan mereka untuk mendapatkan hasil yang akurat. Breiman menambahkan variasi acak tambahan ke dalam prosedur mengantongi, menciptakan keragaman yang lebih besar di antara model yang dihasilkan. Hutan acak berbeda dari pohon yang dikenakan dengan memaksa pohon untuk hanya menggunakan subset dari prediktor yang tersedia untuk dibagi pada fase pertumbuhan. Semua pohon keputusan yang membentuk hutan acak berbeda karena setiap pohon dibangun di atas subset data acak yang berbeda. Karena meminimalkan overfitting, cenderung lebih akurat daripada pohon keputusan tunggal.
Perbedaan antara kantong dan hutan acak
Dasar -dasar
- Baik mengantongi dan hutan acak adalah algoritma berbasis ensemble yang bertujuan untuk mengurangi kompleksitas model yang menguasai data pelatihan. Agregasi Bootstrap, juga disebut Bagging, adalah salah satu metode ensembel tertua dan kuat untuk mencegah overfitting. Ini adalah teknologi meta yang menggunakan beberapa pengklasifikasi untuk meningkatkan akurasi prediktif. Mengantongi hanya berarti menarik sampel acak dari sampel pelatihan untuk diganti untuk mendapatkan ansambel dari berbagai model. Random Forest adalah algoritma pembelajaran mesin yang diawasi berdasarkan pembelajaran ensemble dan evolusi algoritma mengantongi asli Breiman.
Konsep
- Konsep pengambilan sampel bootstrap (mengantongi) adalah untuk melatih sekelompok pohon keputusan yang tidak dipanaskan pada subset acak yang berbeda dari data pelatihan, pengambilan sampel dengan penggantian, untuk mengurangi varian pohon keputusan keputusan keputusan. Idenya adalah untuk menggabungkan prediksi beberapa pelajar dasar untuk membuat output yang lebih akurat. Dengan hutan acak, variasi acak tambahan ditambahkan ke dalam prosedur mengantongi untuk menciptakan keragaman yang lebih besar di antara model yang dihasilkan. Gagasan di balik hutan acak adalah membangun beberapa pohon keputusan dan mengumpulkan mereka untuk mendapatkan hasil yang akurat.
Sasaran
- Baik pohon yang dikantongi dan hutan acak adalah instrumen pembelajaran ensemble yang paling umum digunakan untuk mengatasi berbagai masalah pembelajaran mesin. Bootstrap Sampling adalah meta-algoritma yang dirancang untuk meningkatkan akurasi dan stabilitas model pembelajaran mesin menggunakan pembelajaran ensemble dan mengurangi kompleksitas model overfitting. Algoritma hutan acak sangat kuat terhadap overfitting dan baik dengan data yang tidak seimbang dan hilang. Ini juga merupakan pilihan algoritma yang disukai untuk membangun model prediktif. Tujuannya adalah untuk mengurangi varian dengan rata -rata beberapa pohon keputusan dalam, dilatih pada sampel data yang berbeda.
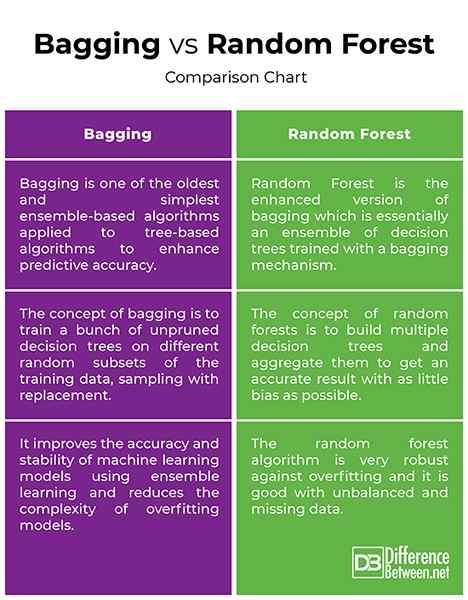
Mengantongi vs. Hutan acak: bagan perbandingan
Ringkasan
Baik pohon yang dikantongi dan hutan acak adalah instrumen pembelajaran ensemble yang paling umum digunakan untuk mengatasi berbagai masalah pembelajaran mesin. Bagging adalah salah satu algoritma berbasis ensemble tertua dan paling sederhana, yang dapat diterapkan pada algoritma berbasis pohon untuk meningkatkan keakuratan prediksi. Hutan acak, di sisi lain, adalah algoritma pembelajaran mesin yang diawasi dan versi yang disempurnakan dari model pengambilan sampel bootstrap yang digunakan untuk masalah regresi dan klasifikasi. Gagasan di balik hutan acak adalah membangun beberapa pohon keputusan dan mengumpulkan mereka untuk mendapatkan hasil yang akurat. Hutan acak cenderung lebih akurat daripada pohon keputusan tunggal karena meminimalkan overfitting.